Os avanços tecnológicos e o barateamento do hardware permitiram que dados fossem gerados e armazenados a um custo acessível. Dados sobre empresas, institutos, pessoas físicas, sensores, etc. atualmente somam um volume gigantesco de dados.

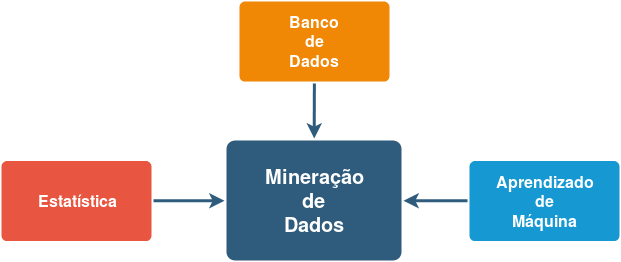
Na década de 1960 pesquisadores começaram a se perguntar se não seria possível extrair informação e conhecimento útil de um grande volume de dados. A conversão de dados brutos em informação e conhecimento permitiria a realização de análises complexas, sínteses, previsões, inferências, etc. Assim, os pesquisadores iniciaram, na década de 1980, o desenvolvimento de ferramentas que resultaram no surgimento da Mineração de Dados, do inglês Data Mining, que integra contribuições de diversas áreas do conhecimento, com destaque para Banco de Dados, Aprendizado de Máquina e Estatística.
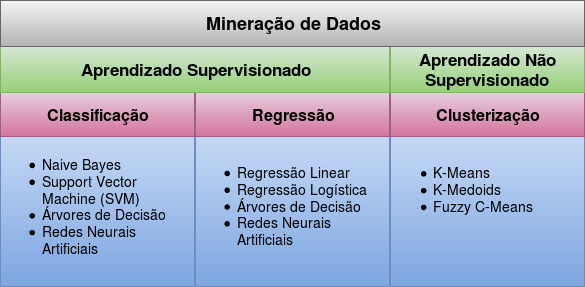
A Mineração de Dados pode ser aplicada a diferentes tarefas. Vamos aqui destacar três delas: Classificação, Regressão e Clusterização. A Classificação é a tarefa do tipo supervisionada utilizada para identifica a qual categoria um determinado documento pertence. Um exemplo é a classificação automática de notícias. Após processar o conteúdo de uma notícia (o documento), o algoritmo poderá classificá-la como entretenimento, política, classificados, economia, .... Dos algoritmos que implementam a Classificação podemos citar o Naive Bayes, Support Vector Machine (SVM), Árvores de Decisão, etc.
A Regressão é uma tarefa supervisionada que tem por objetivo prever um valor futuro analisando valores do passado. Um exemplo são predições realizadas no mercado imobiliário para determinar o preço futuro de um imóvel. Uma outra aplicação é a análise de dados sobre condições de uso e ambiente de um equipamento para prever em quanto tempo ele irá começar a apresentar falhas. Alguns algoritmos que implementam a Regressão são a Regressão Linear, Regressão Logística, Redes Neurais Artificiais, etc.
A Clusterização, também conhecida como Agrupamento, é uma tarefa não supervisionada que visa reunir em grupos documentos de acordo com o grau de semelhança existente entre eles. Um exemplo é a detecção de perfis de clientes. O agrupamento de clientes de acordo com suas preferências, comportamentos, etc. pode ser utilizado para marketing direcionado, prevenção de compras indevidas com cartão de crédito, etc. Os principais algoritmos que implementam a Clusterização são o K-Means, K-Medoids e o Fuzzy C-Means.
Na PROGNIT Cursos temos o Minicurso de Mineração de Dados voltado para as tarefas de Classificação, Predição e Clusterização. No Minicurso de Mineração de Dados voltado à Classificação você irá aprender a implementar um classificador utilizando o Algoritmo de Árvore de Decisão. No Minicurso de Mineração de Dados voltado à Predição você irá aprender a implementar um preditor utilizando o de Regressão Linear. No Minicurso de Mineração de Dados voltado à Clusterização você irá aprender a implementar um clusterizador utilizando o Algoritmo K-Means.
As implementações de todos os minicursos são feitas em Python. Quer saber mais e aprender a implementar o seu classificador, preditor e clusterizador? Inscreva-se em nossos minicursos:
Introdução à Mineração de Dados com Aplicações em Ciências Ambientais e Espaciais
A Survey on the Machine Learning Techniques for the News Classification
Previsão de Falhas em Redes de Distribuição de Água
Fraud Detection in Credit Card by Clustering Approach
